La recherche expérimentale, souvent considérée comme » l’étalon-or » des plans de recherche, est l’un des plans de recherche les plus rigoureux. Dans ce modèle, une ou plusieurs variables indépendantes sont manipulées par le chercheur (en tant que traitements), les sujets sont affectés de manière aléatoire à différents niveaux de traitement (affectation aléatoire), et les résultats des traitements sur les résultats (variables dépendantes) sont observés. La force unique de la recherche expérimentale est sa validité interne (causalité) due à sa capacité à relier la cause et l’effet par la manipulation du traitement, tout en contrôlant l’effet fallacieux de la variable étrangère.
La recherche expérimentale convient mieux à la recherche explicative (plutôt qu’à la recherche descriptive ou exploratoire), où le but de l’étude est d’examiner les relations de cause à effet. Elle est également efficace pour les recherches qui impliquent un ensemble relativement limité et bien défini de variables indépendantes qui peuvent être manipulées ou contrôlées. La recherche expérimentale peut être menée en laboratoire ou sur le terrain. Les expériences en laboratoire, menées dans des environnements de laboratoire (artificiels), ont tendance à avoir une validité interne élevée, mais au prix d’une faible validité externe (généralisabilité), car l’environnement artificiel (laboratoire) dans lequel l’étude est menée peut ne pas refléter le monde réel. Les expériences sur le terrain, menées dans des contextes de terrain tels que ceux d’une organisation réelle, ont une validité interne et externe élevée. Mais ces expériences sont relativement rares, en raison des difficultés associées à la manipulation des traitements et au contrôle des effets étrangers dans un cadre de terrain.
Les recherches expérimentales peuvent être regroupées en deux grandes catégories : les véritables plans expérimentaux et les plans quasi-expérimentaux. Les deux conceptions nécessitent une manipulation du traitement, mais si les vraies expériences nécessitent également une affectation aléatoire, les quasi-expériences ne le font pas. Parfois, nous faisons également référence à la recherche non expérimentale, qui n’est pas vraiment un modèle de recherche, mais un terme global qui inclut tous les types de recherche qui ne font pas appel à la manipulation du traitement ou à l’affectation aléatoire, comme la recherche par sondage, la recherche par observation et les études corrélationnelles.
Concepts de base
Groupes de traitement et de contrôle. Dans la recherche expérimentale, certains sujets reçoivent un ou plusieurs stimulus expérimentaux appelés traitement (le groupe de traitement ) tandis que d’autres sujets ne reçoivent pas un tel stimulus (le groupe témoin ). Le traitement peut être considéré comme réussi si les sujets du groupe de traitement ont une opinion plus favorable des variables de résultat que les sujets du groupe de contrôle. Plusieurs niveaux de stimulus expérimental peuvent être administrés, auquel cas il peut y avoir plus d’un groupe de traitement. Par exemple, pour tester les effets d’un nouveau médicament destiné à traiter une certaine maladie comme la démence, si un échantillon de patients atteints de démence est divisé au hasard en trois groupes, le premier groupe recevant un dosage élevé du médicament, le deuxième groupe recevant un dosage faible, et le troisième groupe recevant un placebo tel qu’une pilule de sucre (groupe témoin), alors les deux premiers groupes sont des groupes expérimentaux et le troisième groupe est un groupe témoin. Après avoir administré le médicament pendant un certain temps, si l’état des sujets du groupe expérimental s’améliore significativement plus que celui des sujets du groupe témoin, on peut dire que le médicament est efficace. Nous pouvons également comparer les conditions des groupes expérimentaux à forte et faible dose pour déterminer si la forte dose est plus efficace que la faible dose.
Manipulation du traitement. Les traitements sont la caractéristique unique de la recherche expérimentale qui distingue cette conception de toutes les autres méthodes de recherche. La manipulation du traitement permet de contrôler la « cause » dans les relations de cause à effet. Naturellement, la validité de la recherche expérimentale dépend de la façon dont le traitement a été manipulé. La manipulation du traitement doit être vérifiée à l’aide de prétests et de tests pilotes avant l’étude expérimentale. Toutes les mesures effectuées avant l’administration du traitement sont appelées mesures pré-test , tandis que celles effectuées après le traitement sont des mesures post-test .
Sélection et affectation aléatoires. La sélection aléatoire est le processus de tirage aléatoire d’un échantillon à partir d’une population ou d’un cadre d’échantillonnage. Cette approche est généralement employée dans la recherche par sondage, et assure que chaque unité de la population a une chance positive d’être sélectionnée dans l’échantillon. L’assignation aléatoire est cependant un processus qui consiste à assigner de manière aléatoire des sujets à des groupes expérimentaux ou de contrôle. Il s’agit d’une pratique standard dans la véritable recherche expérimentale pour garantir que les groupes de traitement sont similaires (équivalents) les uns aux autres et au groupe de contrôle, avant l’administration du traitement. La sélection aléatoire est liée à l’échantillonnage, et est donc plus étroitement liée à la validité externe (généralisabilité) des résultats. En revanche, l’assignation aléatoire est liée à la conception, et est donc davantage liée à la validité interne. Il est possible d’avoir à la fois une sélection et une affectation aléatoires dans une recherche expérimentale bien conçue, mais la recherche quasi-expérimentale n’implique ni sélection ni affectation aléatoires.
Menaces sur la validité interne. Bien que les conceptions expérimentales soient considérées comme plus rigoureuses que les autres méthodes de recherche en termes de validité interne de leurs inférences (en vertu de leur capacité à contrôler les causes par la manipulation du traitement), elles ne sont pas à l’abri des menaces à la validité interne. Certaines de ces menaces à la validité interne sont décrites ci-dessous, dans le contexte d’une étude de l’impact d’un programme spécial de tutorat en mathématiques de rattrapage pour améliorer les capacités en mathématiques des élèves du secondaire.
- La menace historique est la possibilité que les effets observés (variables dépendantes) soient causés par des événements étrangers ou historiques plutôt que par le traitement expérimental. Par exemple, l’amélioration des résultats des élèves après le rattrapage en mathématiques peut avoir été causée par leur préparation à un examen de mathématiques dans leur école, plutôt que par le programme de rattrapage en mathématiques.
- La menace de la maturation fait référence à la possibilité que les effets observés soient causés par la maturation naturelle des sujets (par ex, une amélioration générale de leur capacité intellectuelle à comprendre des concepts complexes) plutôt que par le traitement expérimental.
- La menace du test est une menace dans les conceptions pré-post où les réponses des sujets au post-test sont conditionnées par leurs réponses au pré-test. Par exemple, si les étudiants se souviennent de leurs réponses lors de l’évaluation pré-test, ils peuvent avoir tendance à les répéter lors de l’examen post-test. Ne pas effectuer de prétest peut aider à éviter cette menace.
- La menace de l’instrumentation , qui se produit également dans les conceptions pré-post, fait référence à la possibilité que la différence entre les scores du prétest et du post-test ne soit pas due au programme de rattrapage en mathématiques, mais à des changements dans le test administré, comme le post-test ayant un degré de difficulté plus ou moins élevé que le prétest.
- La menace de mortalité fait référence à la possibilité que les sujets abandonnent l’étude à des taux différentiels entre les groupes de traitement et de contrôle pour une raison systématique, comme le fait que les abandons étaient principalement des étudiants qui ont obtenu de faibles résultats au prétest. Si les élèves peu performants abandonnent, les résultats du post-test seront artificiellement gonflés par la prépondérance des élèves très performants.
- Menace de régression , également appelée régression à la moyenne, fait référence à la tendance statistique de la performance globale d’un groupe sur une mesure au cours d’un post-test à régresser vers la moyenne de cette mesure plutôt que dans la direction prévue. Par exemple, si les sujets ont obtenu un score élevé au prétest, ils auront tendance à obtenir un score plus faible au post-test (plus proche de la moyenne) car leur score élevé (éloigné de la moyenne) au cours du prétest était peut-être une aberration statistique. Ce problème a tendance à être plus répandu dans les échantillons non aléatoires et lorsque les deux mesures sont imparfaitement corrélées.
Des plans expérimentaux à deux groupes
Les véritables plans expérimentaux les plus simples sont les plans à deux groupes impliquant un groupe de traitement et un groupe de contrôle, et sont idéalement adaptés pour tester les effets d’une seule variable indépendante qui peut être manipulée comme un traitement. Les deux plans de base à deux groupes sont le plan de groupe de contrôle prétest-post-test et le plan de groupe de contrôle post-test seulement, mais des variantes peuvent inclure des plans de covariance. Ces conceptions sont souvent représentées à l’aide d’une notation de conception standardisée, où R représente l’affectation aléatoire des sujets aux groupes, X représente le traitement administré au groupe de traitement, et O représente les observations prétest ou posttest de la variable dépendante (avec des indices différents pour distinguer les observations prétest et posttest des groupes de traitement et de contrôle).
Conception de groupe de contrôle prétest-post-test . Dans ce plan, les sujets sont répartis au hasard entre les groupes de traitement et de contrôle, soumis à une mesure initiale (prétest) des variables dépendantes d’intérêt, le groupe de traitement est administré un traitement (représentant la variable indépendante d’intérêt), et les variables dépendantes mesurées à nouveau (post-test). La notation de ce plan est présentée à la figure 10.1.

Figure 10.1. Plan de groupe témoin pré-test-post-test
L’effet E du traitement expérimental dans le plan pré-test post-test est mesuré comme la différence entre les scores du post-test et du pré-test entre les groupes de traitement et de contrôle :
E = (O 2 – O 1 ) – (O 4 – O 3 )
L’analyse statistique de ce plan implique une simple analyse de variance (ANOVA) entre les groupes de traitement et de contrôle. La conception pré-test post-test gère plusieurs menaces à la validité interne, telles que la maturation, le test et la régression, car on peut s’attendre à ce que ces menaces influencent les groupes de traitement et de contrôle de manière similaire (aléatoire). La menace de sélection est contrôlée par l’assignation aléatoire. Cependant, d’autres menaces à la validité interne peuvent exister. Par exemple, la mortalité peut être un problème s’il y a des taux d’abandon différentiels entre les deux groupes, et la mesure du prétest peut biaiser la mesure du post-test (en particulier si le prétest introduit des sujets ou un contenu inhabituels).
Conception de groupe de contrôle post-test uniquement . Ce design est une version plus simple du design prétest-posttest où les mesures du prétest sont omises. La notation du design est présentée à la figure 10.2.

Figure 10.2. Modèle de groupe témoin avec post-test uniquement.
L’effet du traitement est mesuré simplement comme la différence des scores au post-test entre les deux groupes :
E = (O 1 – O 2 )
L’analyse statistique appropriée de ce modèle est également une analyse de variance (ANOVA) à deux groupes. La simplicité de ce plan le rend plus attrayant que le plan prétest-post-test en termes de validité interne. Ce plan contrôle la maturation, le test, la régression, la sélection et l’interaction prétest-post-test, bien que la menace de mortalité puisse continuer à exister.
Des plans de covariance . Parfois, les mesures des variables dépendantes peuvent être influencées par des variables étrangères appelées covariables . Les covariables sont les variables qui ne sont pas d’un intérêt central pour une étude expérimentale, mais qui doivent néanmoins être contrôlées dans un plan expérimental afin d’éliminer leur effet potentiel sur la variable dépendante et donc permettre une détection plus précise des effets des variables indépendantes d’intérêt. Les plans expérimentaux discutés précédemment ne contrôlaient pas ces covariables. Un plan de covariance (également appelé plan à variables concomitantes) est un type particulier de plan de groupe témoin pré-test post-test où la mesure du pré-test est essentiellement une mesure des covariables d’intérêt plutôt que celle des variables dépendantes. La notation du plan est présentée à la figure 10.3, où C représente les covariables:

Figure 10.3. Plan de covariance
Parce que la mesure du prétest n’est pas une mesure de la variable dépendante, mais plutôt une covariable, l’effet du traitement est mesuré comme la différence des scores du post-test entre les groupes de traitement et de contrôle comme:
E = (O 1 – O 2 )
En raison de la présence de covariables, la bonne analyse statistique de ce plan est une analyse de covariance à deux groupes (ANCOVA). Ce plan présente tous les avantages du plan post-test uniquement, mais avec une validité interne due au contrôle des covariables. Les plans de covariance peuvent également être étendus au plan de groupe de contrôle pré-test-post-test. 
Des plans factoriels
Les plans à deux groupes sont inadéquats si votre recherche nécessite la manipulation de deux variables indépendantes (traitements) ou plus. Dans ce cas, vous aurez besoin de plans à quatre groupes ou plus. Ces plans, assez populaires dans la recherche expérimentale, sont communément appelés plans factoriels. Dans ce type de plan, chaque variable indépendante est appelée un facteur, et chaque sous-division d’un facteur est appelée un niveau. Les plans factoriels permettent au chercheur d’examiner non seulement l’effet individuel de chaque traitement sur les variables dépendantes (appelés effets principaux), mais aussi leur effet conjoint (appelés effets d’interaction).
Le plan factoriel le plus basique est un plan factoriel 2 x 2, qui consiste en deux traitements, chacun avec deux niveaux (comme élevé/faible ou présent/absent). Par exemple, disons que vous voulez comparer les résultats d’apprentissage de deux types différents de techniques d’enseignement (enseignement en classe et en ligne), et vous voulez également examiner si ces effets varient en fonction du temps d’enseignement (1,5 ou 3 heures par semaine). Dans ce cas, vous avez deux facteurs : le type d’enseignement et le temps d’enseignement, chacun avec deux niveaux (en classe et en ligne pour le type d’enseignement, et 1,5 et 3 heures par semaine pour le temps d’enseignement), comme le montre la figure 8.1. Si vous souhaitez ajouter un troisième niveau de temps d’enseignement (disons 6 heures/semaine), le deuxième facteur sera composé de trois niveaux et vous aurez un plan factoriel 2 x 3. D’autre part, si vous souhaitez ajouter un troisième facteur tel que le travail de groupe (présent ou absent), vous aurez un plan factoriel 2 x 2 x 2. Dans cette notation, chaque nombre représente un facteur, et la valeur de chaque facteur représente le nombre de niveaux de ce facteur.

Figure 10.4. Plan factoriel 2 x 2
Les plans factoriels peuvent également être représentés à l’aide d’une notation de plan, comme celle illustrée sur le panneau droit de la figure 10.4. R représente l’affectation aléatoire des sujets aux groupes de traitement, X représente les groupes de traitement eux-mêmes (les indices de X représentent le niveau de chaque facteur), et O représente les observations de la variable dépendante. Notez que le plan factoriel 2 x 2 aura quatre groupes de traitement, correspondant aux quatre combinaisons des deux niveaux de chaque facteur. De même, le plan 2 x 3 aura six groupes de traitement, et le plan 2 x 2 x 2 aura huit groupes de traitement. En règle générale, chaque cellule d’un plan factoriel doit avoir une taille d’échantillon minimale de 20 (cette estimation est dérivée des calculs de puissance de Cohen basés sur des tailles d’effet moyennes). Ainsi, un plan factoriel 2 x 2 x 2 nécessite un échantillon total minimum de 160 sujets, avec au moins 20 sujets dans chaque cellule. Comme vous pouvez le constater, le coût de la collecte des données peut augmenter considérablement avec le nombre de niveaux ou de facteurs dans votre plan factoriel. Parfois, en raison de contraintes de ressources, certaines cellules de ces plans factoriels peuvent ne recevoir aucun traitement, ce que l’on appelle des plans factoriels incomplets. Ces plans incomplets nuisent à notre capacité à tirer des inférences sur les facteurs incomplets.
Dans un plan factoriel, on dit qu’il existe un effet principal si la variable dépendante présente une différence significative entre plusieurs niveaux d’un facteur, à tous les niveaux des autres facteurs. Aucun changement de la variable dépendante entre les niveaux de facteurs est le cas nul (ligne de base), à partir duquel les effets principaux sont évalués. Dans l’exemple ci-dessus, vous pouvez voir un effet principal du type d’enseignement, du temps d’enseignement ou des deux sur les résultats d’apprentissage. Un effet d’interaction existe lorsque l’effet des différences dans un facteur dépend du niveau d’un second facteur. Dans notre exemple, si l’effet du type d’enseignement sur les résultats d’apprentissage est plus important pour 3 heures/semaine de temps d’enseignement que pour 1,5 heure/semaine, nous pouvons dire qu’il existe un effet d’interaction entre le type d’enseignement et le temps d’enseignement sur les résultats d’apprentissage. Notez que la présence d’effets d’interaction domine et rend les effets principaux non pertinents, et il n’est pas significatif d’interpréter les effets principaux si les effets d’interaction sont significatifs.
Plans expérimentaux hybrides
Les plans hybrides sont ceux qui sont formés en combinant les caractéristiques de plans plus établis. Trois de ces plans hybrides sont le plan à blocs randomisés, le plan à quatre groupes de Solomon et le plan à répétitions commutées.
Le plan à blocs randomisés. Il s’agit d’une variante du plan à groupe témoin post-test seul ou prétest-post-test dans lequel la population des sujets peut être regroupée en sous-groupes relativement homogènes (appelés blocs ) au sein desquels l’expérience est répliquée. Par exemple, si vous souhaitez reproduire le même plan de type post-test seul parmi des étudiants universitaires et des professionnels travaillant à plein temps (deux blocs homogènes), les sujets des deux blocs sont répartis au hasard entre le groupe de traitement (qui reçoit le même traitement) et le groupe témoin (voir Figure 10.5). L’objectif de ce plan est de réduire le « bruit » ou la variance des données qui peut être attribuable aux différences entre les blocs, de sorte que l’effet réel d’intérêt puisse être détecté avec plus de précision.
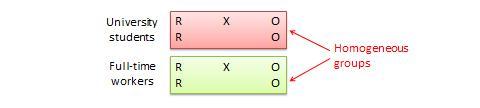
Figure 10.5. Plan en blocs aléatoires.
Plan à quatre groupes de Salomon . Dans ce plan, l’échantillon est divisé en deux groupes de traitement et deux groupes de contrôle. Un groupe de traitement et un groupe témoin reçoivent le prétest, et les deux autres groupes ne le reçoivent pas. Ce plan représente une combinaison du plan de groupe de contrôle post-test seulement et du plan de groupe de contrôle pré-test-post-test, et il est destiné à tester l’effet de biais potentiel de la mesure du pré-test sur les mesures du post-test qui tend à se produire dans les plans pré-test-post-test mais pas dans les plans post-test seulement. La notation du plan est présentée à la figure 10.6.

Figure 10.6. Plan à quatre groupes de Solomon
Plan de réplication commuté . Il s’agit d’un plan à deux groupes mis en œuvre en deux phases avec trois vagues de mesure. Le groupe de traitement de la première phase sert de groupe témoin dans la deuxième phase, et le groupe témoin de la première phase devient le groupe de traitement de la deuxième phase, comme l’illustre la figure 10.7. En d’autres termes, la conception originale est répétée ou reproduite dans le temps avec une permutation des rôles de traitement et de contrôle entre les deux groupes. A la fin de l’étude, tous les participants auront reçu le traitement soit pendant la première, soit pendant la deuxième phase. Ce plan est le plus réalisable dans les contextes organisationnels où les programmes organisationnels (par exemple, la formation des employés) sont mis en œuvre de manière progressive ou sont répétés à intervalles réguliers.
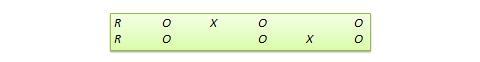
Figure 10.7. Plan de réplication commuté.
Plans quasi-expérimentaux
Les plans quasi-expérimentaux sont presque identiques aux vrais plans expérimentaux, mais il leur manque un ingrédient clé : l’affectation aléatoire. Par exemple, une section de classe entière ou une organisation est utilisée comme groupe de traitement, tandis qu’une autre section de la même classe ou une organisation différente dans le même secteur d’activité est utilisée comme groupe de contrôle. Cette absence d’affectation aléatoire peut donner lieu à des groupes non équivalents, par exemple un groupe qui maîtrise mieux un certain contenu que l’autre groupe, par exemple parce qu’il a eu un meilleur professeur au semestre précédent, ce qui introduit la possibilité d’un biais de sélection. Les plans quasi-expérimentaux sont donc inférieurs aux vrais plans expérimentaux en termes de validité d’intervalle, en raison de la présence d’une variété de menaces liées à la sélection, telles que la menace de la sélection-maturation (les groupes de traitement et de contrôle mûrissent à des rythmes différents), la menace de la sélection-historique (les groupes de traitement et de contrôle sont influencés de manière différente par des événements étrangers ou historiques), la menace de la sélection-régression (les groupes de traitement et de contrôle régressent vers la moyenne entre le prétest et le post-test à des rythmes différents), la menace de la sélection-instrumentation (les groupes de traitement et de contrôle réagissent différemment à la mesure), la sélection-test (les groupes de traitement et de contrôle réagissent différemment au prétest) et la sélection-mortalité (les groupes de traitement et de contrôle présentent des taux d’abandon différents). Compte tenu de ces menaces de sélection, il est généralement préférable d’éviter les plans quasi-expérimentaux dans la mesure du possible.
De nombreux plans expérimentaux véritables peuvent être convertis en plans quasi-expérimentaux en omettant l’affectation aléatoire. Par exemple, la version quasi-équivalente du plan de groupe témoin prétest-post-test est appelée plan de groupes non équivalents (NEGD), comme le montre la figure 10.8, l’affectation aléatoire R étant remplacée par une affectation non équivalente (non aléatoire) N . De même, la version quasi -expérimentale du plan de réplication commuté est appelée plan de réplication commuté non équivalent (voir figure 10.9).

Figure 10.8. Conception NEGD.
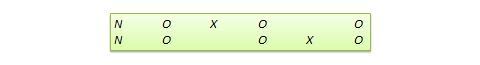
Figure 10.9. Plan de réplication commuté non équivalent.
En outre, il existe un assez grand nombre de plans non -équivalents uniques sans cousins véritables plans expérimentaux correspondants. Certains des plus utiles de ces plans sont abordés ci-après.
Le plan de régression-discontinuité (RD) . Il s’agit d’un plan non équivalent de type prétest-post-test dans lequel les sujets sont affectés au groupe de traitement ou de contrôle en fonction d’un score seuil sur une mesure préalable au programme. Par exemple, les patients gravement malades peuvent être affectés à un groupe de traitement pour tester l’efficacité d’un nouveau médicament ou d’un nouveau protocole de traitement, tandis que ceux qui sont légèrement malades sont affectés au groupe témoin. Dans un autre exemple, les étudiants qui sont en retard dans les résultats de tests standardisés peuvent être sélectionnés pour un programme de rattrapage destiné à améliorer leurs performances, tandis que ceux qui obtiennent des résultats élevés à ces tests ne sont pas sélectionnés dans le programme de rattrapage. La notation du design peut être représentée comme suit, où C représente le score de coupure:
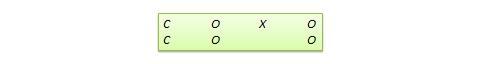
Figure 10.10. Conception du RD.
En raison de l’utilisation d’un score de coupure, il est possible que les résultats observés soient fonction du score de coupure plutôt que du traitement, ce qui introduit une nouvelle menace pour la validité interne. Cependant, l’utilisation d’un score de seuil garantit également que les ressources limitées ou coûteuses sont distribuées aux personnes qui en ont le plus besoin plutôt qu’au hasard dans une population, tout en permettant simultanément un traitement quasi-expérimental. Les scores du groupe témoin dans le plan RD ne servent pas de référence pour comparer les scores du groupe de traitement, étant donné la non-équivalence systématique entre les deux groupes. Au contraire, s’il n’y a pas de discontinuité entre les scores du prétest et du post-test dans le groupe de contrôle, mais qu’une telle discontinuité persiste dans le groupe de traitement, alors cette discontinuité est considérée comme une preuve de l’effet du traitement.
Le design de prétest par procuration . Ce plan, illustré à la figure 10.11, ressemble beaucoup au plan standard NEGD (prétest-post-test), à une différence essentielle près : le score du prétest est recueilli après l’administration du traitement. Une application typique de ce modèle est le cas où un chercheur est amené à tester l’efficacité d’un programme (par exemple, un programme éducatif) après que le programme a déjà commencé et que les données du prétest ne sont pas disponibles. Dans ces circonstances, la meilleure option pour le chercheur est souvent d’utiliser une autre mesure préenregistrée, telle que la moyenne générale des étudiants avant le début du programme, comme substitut des données du prétest. Une variante de la conception de prétest par procuration consiste à utiliser le souvenir post-test des sujets des données du prétest, qui peut être sujet à un biais de rappel, mais qui peut néanmoins fournir une mesure du gain ou du changement perçu dans la variable dépendante.
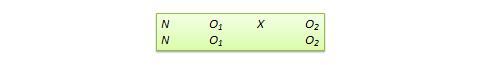
Figure 10.11. Plan de prétest par procuration.
Plan d’échantillons prétest-post-test distincts . Ce plan est utile si, pour une raison quelconque, il n’est pas possible de collecter des données prétest et post-test auprès des mêmes sujets. Comme le montre la figure 10.12, il y a quatre groupes dans ce plan, mais deux groupes proviennent d’un seul groupe non équivalent, tandis que les deux autres groupes proviennent d’un groupe non équivalent différent. Par exemple, vous souhaitez tester la satisfaction des clients à l’égard d’un nouveau service en ligne qui est mis en place dans une ville mais pas dans une autre. Dans ce cas, les clients de la première ville servent de groupe de traitement et ceux de la deuxième ville constituent le groupe de contrôle. S’il n’est pas possible d’obtenir des mesures pré-test et post-test auprès des mêmes clients, vous pouvez mesurer la satisfaction des clients à un moment donné, mettre en œuvre le nouveau programme de service, et mesurer la satisfaction des clients (avec un ensemble différent de clients) après la mise en œuvre du programme. La satisfaction des clients est également mesurée dans le groupe de contrôle aux mêmes moments que dans le groupe de traitement, mais sans la mise en œuvre du nouveau programme. Cette conception n’est pas particulièrement solide, car il n’est pas possible d’examiner les changements dans le score de satisfaction d’un client spécifique avant et après la mise en œuvre, mais seulement les scores moyens de satisfaction des clients. Malgré une validité interne plus faible, ce plan peut tout de même constituer un moyen utile de collecter des données quasi-expérimentales lorsque les données du prétest et du post-test ne sont pas disponibles pour les mêmes sujets.

Figure 10.12. Plan d’échantillonnage prétest-post-test séparé.
Plan d’échantillonnage à variable dépendante non équivalente (VDNE) . Il s’agit d’un plan quasi-expérimental pré-post à groupe unique avec deux mesures de résultats, où l’une des mesures est théoriquement censée être influencée par le traitement et l’autre non. Par exemple, si vous concevez un nouveau programme de calcul pour les élèves du secondaire, ce programme est susceptible d’influencer les résultats du post-test en calcul mais pas en algèbre. Cependant, les scores d’algèbre du post-test peuvent encore varier en raison de facteurs étrangers tels que l’histoire ou la maturation. Par conséquent, les scores d’algèbre pré-post peuvent être utilisés comme mesure de contrôle, tandis que ceux de calcul pré-post peuvent être traités comme mesure de traitement. La notation du plan d’étude, illustrée à la figure 10.13, indique le groupe unique par un seul N , suivi du prétest O 1 et du post-test O 2 pour le calcul et l’algèbre pour le même groupe d’étudiants. Ce plan est faible en termes de validité interne, mais son avantage réside dans le fait qu’il n’est pas nécessaire d’utiliser un groupe de contrôle distinct.
Une variante intéressante du plan NEDV est un plan NEDV à correspondance de modèle , qui emploie plusieurs variables de résultat et une théorie qui explique dans quelle mesure chaque variable sera affectée par le traitement. Le chercheur peut ensuite examiner si la prédiction théorique correspond aux observations réelles. Cette technique d’appariement des modèles, basée sur le degré de correspondance entre les modèles théoriques et observés, est un moyen puissant d’atténuer les problèmes de validité interne du modèle NEDV original.
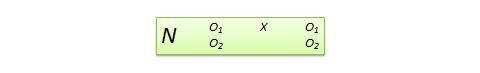
Figure 10.13. Conception NEDV.
Les périls de la recherche expérimentale
La recherche expérimentale est l’une des conceptions de recherche les plus difficiles, et ne doit pas être prise à la légère. Ce type de recherche est souvent le meilleur avec une multitude de problèmes méthodologiques. Tout d’abord, bien que la recherche expérimentale nécessite des théories pour formuler des hypothèses à tester, une grande partie de la recherche expérimentale actuelle est athéorique. Sans théories, les hypothèses testées ont tendance à être ad hoc, éventuellement illogiques et dénuées de sens. Deuxièmement, la fiabilité et la validité de nombreux instruments de mesure utilisés dans la recherche expérimentale ne sont pas testées et ces instruments ne sont pas comparables d’une étude à l’autre. Par conséquent, les résultats obtenus à l’aide de ces instruments sont également incomparables. Troisièmement, de nombreuses recherches expérimentales utilisent des plans de recherche inappropriés, tels que des variables dépendantes non pertinentes, aucun effet d’interaction, aucun contrôle expérimental et des stimuli non équivalents entre les groupes de traitement. Les résultats de ces études ont tendance à manquer de validité interne et sont très suspects. Quatrièmement, les traitements (tâches) utilisés dans la recherche expérimentale peuvent être divers, incomparables et incohérents d’une étude à l’autre et parfois inadaptés à la population des sujets. Par exemple, on demande souvent à des étudiants de premier cycle de prétendre qu’ils sont des directeurs de marketing et de réaliser une tâche complexe d’allocation budgétaire pour laquelle ils n’ont aucune expérience ou expertise. L’utilisation de telles tâches inappropriées, introduit de nouvelles menaces pour la validité interne (c’est-à-dire que la performance du sujet peut être un artefact du contenu ou de la difficulté du cadre de la tâche), génère des résultats non interprétables et dénués de sens, et rend impossible l’intégration des résultats entre les études.
La conception de traitements expérimentaux adéquats est une tâche très importante dans la conception expérimentale, car le traitement est la raison d’être de la méthode expérimentale, et ne doit jamais être précipité ou négligé. Pour concevoir une tâche adéquate et appropriée, les chercheurs doivent utiliser des tâches prévalidées si elles sont disponibles, effectuer des contrôles de manipulation du traitement pour vérifier l’adéquation de ces tâches (en débriefant les sujets après avoir effectué la tâche assignée), effectuer des tests pilotes (à plusieurs reprises, si nécessaire) et, en cas de doute, utiliser des tâches plus simples et familières pour l’échantillon de répondants que des tâches complexes ou peu familières.
En résumé, ce chapitre a présenté les concepts clés de la méthode de recherche de la conception expérimentale et a présenté une variété de véritables conceptions expérimentales et quasi-expérimentales. Bien que ces plans varient largement en termes de validité interne, les plans dont la validité interne est moindre ne doivent pas être négligés et peuvent parfois être utiles dans des circonstances et des contingences empiriques spécifiques.
Il s’agit d’une méthode de recherche expérimentale.