| Attributo geometrico | α-elica | 310 elica | π-elica |
|---|---|---|---|
| Residui per giro | 3.6 | 3.0 | 4.4 |
| Traslazione per residuo | 1.5 Å (0.15 nm) | 2.0 Å (0.20 nm) | 1.1 Å (0.11 nm) |
| Radius of helix | 2.3 Å (0.23 nm) | 1.9 Å (0.19 nm) | 2.8 Å (0.28 nm) |
| Passo | 5.4 Å (0.54 nm) | 6.0 Å (0.60 nm) | 4.8 Å (0.48 nm) |
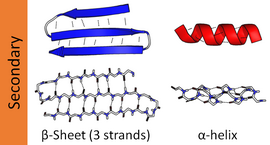
Diagramma interattivo dei legami idrogeno nella struttura secondaria delle proteine. Cartoon sopra, atomi sotto con azoto in blu, ossigeno in rosso (PDB: 1AXC)
Le strutture secondarie più comuni sono le eliche alfa e i fogli beta. Altre eliche, come l’elica 310 e l’elica π, sono calcolate per avere modelli di legami a idrogeno energeticamente favorevoli, ma sono raramente osservate nelle proteine naturali, tranne che alle estremità delle eliche α, a causa dell’imballaggio sfavorevole della spina dorsale al centro dell’elica. Altre strutture estese come l’elica di poliprolina e il foglio alfa sono rare nelle proteine allo stato nativo ma sono spesso ipotizzate come importanti intermedi di ripiegamento delle proteine. Giravolte strette e loop sciolti e flessibili collegano gli elementi della struttura secondaria più “regolare”. La spirale casuale non è una vera struttura secondaria, ma è la classe di conformazioni che indicano un’assenza di struttura secondaria regolare.
Gli aminoacidi variano nella loro capacità di formare i vari elementi di struttura secondaria. La prolina e la glicina sono a volte conosciute come “helix breakers” perché interrompono la regolarità della conformazione α elicoidale della spina dorsale; tuttavia, entrambe hanno capacità conformazionali insolite e si trovano comunemente in curva. Gli amminoacidi che preferiscono adottare conformazioni elicoidali nelle proteine includono metionina, alanina, leucina, glutammato e lisina (“MALEK” nei codici a 1 lettera degli amminoacidi); al contrario, i grandi residui aromatici (triptofano, tirosina e fenilalanina) e gli amminoacidi ramificati Cβ (isoleucina, valina e treonina) preferiscono adottare conformazioni a filamento β. Tuttavia, queste preferenze non sono abbastanza forti da produrre un metodo affidabile per predire la struttura secondaria dalla sola sequenza.
Le vibrazioni collettive a bassa frequenza sono ritenute sensibili alla rigidità locale nelle proteine, rivelando che le strutture beta sono genericamente più rigide delle proteine alfa o disordinate. Misure di scattering neutronico hanno collegato direttamente la caratteristica spettrale a ~1 THz ai movimenti collettivi della struttura secondaria della proteina GFP.
I modelli di legame a idrogeno nelle strutture secondarie possono essere significativamente distorti, il che rende difficile la determinazione automatica della struttura secondaria. Ci sono diversi metodi per definire formalmente la struttura secondaria delle proteine (ad esempio, DSSP, DEFINE, STRIDE, ScrewFit, SST).
Classificazione DSSPModifica

Il Dictionary of Protein Secondary Structure, in breve DSSP, è comunemente usato per descrivere la struttura secondaria delle proteine con codici a lettera singola. La struttura secondaria viene assegnata in base ai modelli di legame a idrogeno come quelli inizialmente proposti da Pauling et al. nel 1951 (prima che qualsiasi struttura proteica fosse mai stata determinata sperimentalmente). Ci sono otto tipi di struttura secondaria che DSSP definisce:
- G = elica a 3 giri (310 elica). Lunghezza minima 3 residui.
- H = elica a 4 giri (α elica). Lunghezza minima 4 residui.
- I = elica a 5 giri (π helix). Lunghezza minima 5 residui.
- T = giro legato a idrogeno (3, 4 o 5 giri)
- E = filo esteso in conformazione β-sheet parallelo e/o antiparallelo. Lunghezza minima 2 residui.
- B = residuo in β-bridge isolato (formazione di legami a idrogeno a coppia singola in β-sheet)
- S = curva (l’unica assegnazione non basata su legami a idrogeno).
- C = bobina (residui che non sono in nessuna delle conformazioni precedenti).
‘Bobina’ è spesso codificata come ‘ ‘ (spazio), C (coil) o ‘-‘ (trattino). Le conformazioni ad elica (G, H e I) e a foglio devono tutte avere una lunghezza ragionevole. Questo significa che 2 residui adiacenti nella struttura primaria devono formare lo stesso schema di legame a idrogeno. Se il modello di legame a idrogeno dell’elica o del foglio è troppo corto, sono designati come T o B, rispettivamente. Esistono altre categorie di assegnazione della struttura secondaria delle proteine (curve strette, loop Omega, ecc.), ma sono usate meno frequentemente.
La struttura secondaria è definita dal legame a idrogeno, quindi la definizione esatta di un legame a idrogeno è critica. La definizione standard di legame a idrogeno per la struttura secondaria è quella di DSSP, che è un modello puramente elettrostatico. Esso assegna cariche di ±q1 ≈ 0,42e al carbonio carbonilico e all’ossigeno, rispettivamente, e cariche di ±q2 ≈ 0,20e all’idrogeno ammidico e all’azoto, rispettivamente. L’energia elettrostatica è
E = q 1 q 2 ( 1 r O N + 1 r C H – 1 r O H – 1 r C N ) ⋅ 332 kcal/mol . E=q_{1}q_{2}left({frac {1}{r_{mathrm {ON} +{frac {1}{r_{mathrm {CH} {\frac {1}-{frac {1}{r_{{mathrm {OH}} {\frac {1}-{frac {1}{r_{mathrm {CN}} )\cdot 332{testo{ kcal/mol}.}

Secondo il DSSP, un legame a idrogeno esiste se e solo se E è inferiore a -0,5 kcal/mol (-2,1 kJ/mol). Sebbene la formula DSSP sia un’approssimazione relativamente grezza dell’energia fisica del legame a idrogeno, è generalmente accettata come strumento per definire la struttura secondaria.
Classificazione SSTModifica
SST è un metodo bayesiano per assegnare la struttura secondaria ai dati delle coordinate proteiche usando il criterio di informazione di Shannon dell’inferenza della lunghezza minima del messaggio (MML). SST tratta qualsiasi assegnazione di struttura secondaria come un’ipotesi potenziale che tenta di spiegare (comprimere) dati di coordinate proteiche. L’idea centrale è che la migliore assegnazione di struttura secondaria è quella che può spiegare (comprimere) le coordinate di una data proteina nel modo più economico, collegando così l’inferenza della struttura secondaria alla compressione dei dati senza perdita. SST delinea accuratamente qualsiasi catena proteica in regioni associate ai seguenti tipi di assegnazione:
- E = Filo (esteso) di un foglio β-pleato
- G = 310 elica destrorsa
- H = α-elica destrorsa
- I = π-elica destrorsa
- g = 310 elica sinistra
- h = α-elica sinistrorsaα-elica mancina
- i = π-elica mancina
- 3 = 310-like Turn
- 4 = α-like Turn
- 5 = π-like Turn
- T = Unspecified Turn
- C = Coil
- – = Residuo non assegnato